
Over the last few years data and analytics risen to become a top priority in the boardroom. Artificial Intelligence (AI) is now discussed everywhere in business and is now seen by many stakeholders as a key contributor to achieving strategic business goals. This is particularly the case with respect to improving customer experience as companies seek to keep customers happy and increase their value in a world where switching to a competitor at the touch of a mobile phone screen has become so easy. AI is also actively being utilised looked at to help optimise and automate various aspects of business operations to reduce cost.
The amount of money business stakeholders are investing in data and AI continues to grow and is happening with increased urgency more so on the cloud (rather than in the data centre) where companies can get up and running quickly with next to no capital expenditure.
However, despite the investment, problems have emerged. For example, the data landscape has become more complex. More data is coming into the enterprise and is now being persisted in multiple types of data store in the data centre, in multiple clouds and even at the edge on IOT platforms and devices. In addition, the money being invested is often handed out to different business department managers who have purchased their own tools to implement data and analytics development in their respective parts of the business. The result is that many different tools are now in use around the enterprise to connect to data stores across the distributed data landscape, to prepare and integrate that data and to support data scientists in their development of machine learning models.
The result of all this activity is that although progress is being made, two major problems are emerging. The first is often referred to as ‘data sprawl’. Data has become distributed making it much data harder to find, harder to govern and harder to integrate. Yet expectation is that people must ‘just know’ where it is. It has become obvious that this is not the case. Also, in the past, data governance has often been ignored or given low priority and people are beginning to realise that if they don’t know where to find the data and If the data is not trusted then the analytics won’t be either.
The second problem is that although there is a lot of activity and investment going in AI of, the development of machine learning models using many different tools purchased by different business departments has resulted in a fractured AI environment that is not integrated. Furthermore, the speed at which new algorithms are emerging in data science has meant that some technologies used in business have become short lived. Therefore, not only are many companies dealing with the problem of fractured approach to data science, but also that there many different algorithms, code libraries and versions of code in use across multiple tools that are not particularly well managed.
Left alone, this kind of self-service ‘free for all’ can ultimately lead to chaos and real lack of trust in data as shown in Figure 1.
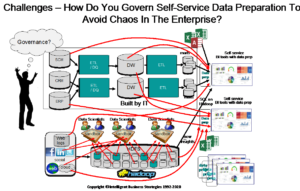
It can become a real obstacle in the way of progressing to a robust and agile operating model for producing high value data and analytics. In some cases, lack of trust in data can get so bad that it stalls deployment of trained machine learning models into production or slows it down so much that very little is used to drive new business value. In addition, most data scientists are focussed on model development and not model deployment into production environments. This combination of issues can lead to project failure with business stakeholders getting increasingly frustrated at the lack of return on their investment. You can see this in recent surveys where data management and data governance are now higher priority that analytics. In my 4th Industrial Revolution Survey Report of 500 enterprises done for the Big Data LDN conference in November 2019, it shows quite clearly that data quality, data governance, and data tools are higher priority than analytics. 41.2% of companies surveyed said that data quality was their number one priority followed by the need to establish data governance (37.8%) and data tools (35%) – see Figure 2. Data skills and productivity were also deemed important.

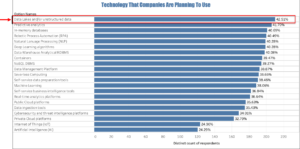
Also, the top technology that companies said they planned to use to get themselves on a more robust footing was data lakes (42.5%) followed by predictive analytics and in-memory databases (Figure 3).
So what is it you need to do to sort this out? How do you pull together independent projects across multiple business units? How do you, find out where your data is and govern it to enable AI to become more successful. How do you industrialise this. Companies need to think about
- Creating an AI strategy for maximum business success
- Enabling value driven data governance in a distributed data landscape
- Data governance automation using Artificial Intelligence and data governance services
- Integrating cloud into your data architecture
- Organising your data lake to avoid data chaos
- Increasing the move to streaming real-time data
- Industrialising and automating model deployment and pipeline development using Enterprise MLOps and DataOps
- Moving towards component based development of data pipelines and data Warehouses
- Integrating Your Data Lake and Data Warehouse on-premises and on the cloud
- Establishing a customer data platform to improve customer experience using data and AI
- Transitioning to a continuous self-learning enterprise using next generation AI
All of this will be discussed at TTI’s Italian Big Data Conference in 3-4 December 2020. I hope you can join us.