
In today’s digital enterprise, data and analytics are now widely recognised as being strategically important in contributing to new business value. In most enterprises this has already been become very high priority in the board room given that C-level approval of investment in AI and data management has soared in last two years. Everywhere I go now, in my clients, I see data science projects underway to build predictive and prescriptive analytical models for various purposes e.g. to reduce fraud, predict customer churn, prevent unplanned equipment failure etc. The problem is that the number of technologies being used to develop these machine learning and deep learning models in a single company is very broad. It ranges from Jupyter notebooks with hand-coded Python and Spark MLlib to drag and drop workflow-based data mining tools to machine learning automation products. Open source libraries galore have sprung up everywhere as new algorithms have emerged enabling us to do traditional clustering, anomaly detection, and predictions at scale and to go way beyond that to do things facial recognition and video analytics.
For many of these companies, data science started out as a number of standalone, piecemeal model development projects. Small teams sprung up in various business units focussed on building models for a specific business purpose. Almost all of these teams requested access to ‘all the raw data’ and to be left alone with whatever technologies they chose to get on with model development. While this decentralised approach was assumed to be the way forward, for many organisations, the creation of autonomous data science teams in different parts of the business, each doing their own thing, has ended up looking somewhat like ‘the wild west’ with everyone buying their own technologies, copying and preparing their own data with no attempt to share what they create. The result is that re-invention is everywhere, speed of development is slow with collaboration lacking. Almost all the focus seems to be on model development with very little on model deployment. The result is frustration among business executives who feel that the length of time it is taking to get models into production is not in line with expectations on the value that should be coming from AI by now given the size and urgency of the investment.
If you recognise any of this, you are not alone. If companies are to really deliver value in a timely manner that meets expectation, they need to accelerate the process of model development and find a much faster way to deploy machine learning models into production so that the business value can be realised. In short, they need a Continuous Integration / Continuous Deployment (CI/CD) approach to building and deploying trusted, reusable data services and also analytical models as a service.
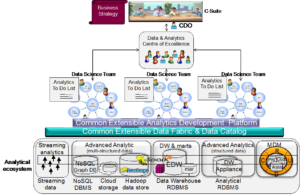
The question is how do they achieve this? A key factor is to recognise that it requires much more than technology to solve this problem. In fact, the hardest part is organising people to make this happen. What is the best approach to organising to succeed? Right across Europe, we have already seen that centralised IT organisations have failed to keep pace with business demand. Equally, running up the other end of the spectrum, and creating a distributed organisation of multiple stand-alone departmental or business unit teams is also sub-optimal and causing technology overspend, re-invention, and to some extent, data chaos with stand-alone self-service data preparation everywhere. Having recently reviewed the set-up for one of my clients, the conclusion was that almost everyone was blindly integrating data with no attempt to what they create. This is the ‘wild west’ we spoke about earlier. So, there needs to be some middle ground. If we are to accelerate the end-to-end- process from data to value, I believe there needs to be a top-down federated organisation structure (shown below) headed up by a Chief Data Officer (CDO) who organises a programme of work to help achieve high priority strategic business objectives.
In a recent survey of 500 enterprises, improving customer experience was the number one strategic business driver for investing in data and analytics. You might then ask:
- What data sets should be created to improve customer experience?
- What predictive models need to be built to improve customer experience?
- What prescriptive models need to be built to automatically make recommendations that improve customer experience?
- Which ones should run in real-time?
- Which ones should run in batch?
- Which ones should run at the edge? Or on the cloud? Or in the data centre?
- What BI reports and dashboards need to be built to improve customer experience?
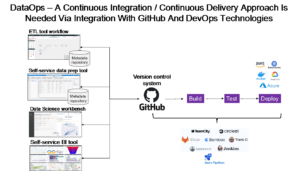
As you can see, a whole family of artefacts need to be built to improve customer experience. The next question is who is building what and in what order? And, can they do it using a common data fabric and data catalog using a common analytical development platform. Or at the very least, if the components are being built using different technologies, who is managing version control of all of these things and orchestrating all these components to automatically and continuously test and deploy everything on a continuous basis to make it happen? Both organisation and orchestration are needed enable continuous development and continuous deployment (CI/CD) DataOps approach. That means data fabric software (comprising ETL and self-service data preparation tools), data science tools and BI tools all need to integrate with a common version management capability like GitHub and with DevOps technologies like Jenkins to automate testing and deployment in order to enable DataOps. In addition, all these components need to registered in a catalog as services so that they can be found and re-used as and when needed. This is already happening with some vendors. Furthermore, several Data Fabric products now offer orchestration to link these components together in end-to-end a CI/CD pipeline so that we can manage component development in different teams as well as automate testing and deployment to help shorten the time to value.
I shall be talking about this and all its related topics in my seminars on Designing, Operating and Managing a Multi-Purpose Data Lake and on Machine Learning and Advanced Analytics, both of which are running in Rome in June. I hope you can join me.