
Nelle digital enterprise di oggi, dati e analytics sono ormai riconosciuti da più parti come strategicamente importanti nel contribuire al nuovo valore di business. Nella maggior parte delle aziende questo è già diventato una priorità molto alta anche a livello di board, in quanto l’approvazione di tipo C-level degli investimenti nell’intelligenza artificiale e nella gestione dei dati è aumentata vertiginosamente negli ultimi due anni. Ovunque io vada oggi, presso i miei clienti, vedo progetti di data science in corso per costruire modelli analitici predittivi e prescrittivi per vari scopi: per esempio, per ridurre le frodi, prevedere la riduzione del numero di clienti, prevenire guasti imprevisti alle apparecchiature, e tanto altro.
Il problema è che il numero di tecnologie utilizzate per sviluppare questi modelli di deep learning e di machine learning in una singola azienda è molto ampio: spazia dai notebook Jupyter con Python e Spark MLlib codificati a mano agli strumenti di data mining di tipo drag & drop basati sui flussi di lavoro, fino ad arrivare ai prodotti di automazione di machine learning. Numerose librerie open source sono sorte ovunque, sulla base dei nuovi algoritmi emersi, che consentono di fare clustering tradizionale, rilevamento di anomalie, previsioni su larga scala e di andare ancora oltre, per fare riconoscimento facciale o analisi dei video.
Integrazione e distribuzione continua
Per molte di queste aziende, la data science è iniziata con numerosi progetti di sviluppo di modelli autonomi e frammentari, con piccoli team sorti in varie unità aziendali focalizzati sulla costruzione di modelli per uno scopo di business specifico. Quasi tutti questi team hanno richiesto l’accesso a “tutti i dati non elaborati” e di essere lasciati soli con qualsiasi tecnologia scelta per andare avanti con lo sviluppo del modello. Mentre questo approccio decentralizzato è stato assunto come la via da seguire, per molte aziende la creazione di team autonomi di data science in diverse parti del business, ognuna facendo le proprie cose, ha finito per sembrare un po’ come il selvaggio West, con tutti che acquistano le proprie tecnologie, copiando e preparando i propri dati senza tentare di condividere ciò che creano. Il risultato è che la reinvenzione è all’ordine del giorno, la velocità di sviluppo è lenta e manca la collaborazione. Quasi tutta l’attenzione si concentra sullo sviluppo del modello, mentre pochissima viene riservata alla distribuzione del modello.
Il risultato è la frustrazione tra i manager del business che ritengono che il tempo impiegato per mettere in produzione i modelli non sia in linea con le aspettative sul valore che dovrebbe provenire dall’AI, vista ormai la dimensione e l’urgenza dell’investimento. Chi trova qualcosa di familiare in tutto questo, non è il solo.
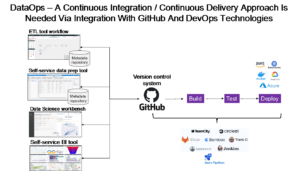
Se le aziende devono davvero fornire valore in modo tempestivo e in linea con le aspettative, devono accelerare il processo di sviluppo del modello e trovare un modo molto più veloce per mettere in produzione i modelli di apprendimento automatico, in modo da poter ottenere valore di business. In breve, hanno bisogno di un approccio di integrazione continua/distribuzione continua (CI/CD, continuous integration/continuous development) per la costruzione e l’implementazione di servizi dati affidabili e riutilizzabili, oltre che di modelli analitici come servizio.
Come raggiungere l’obiettivo?
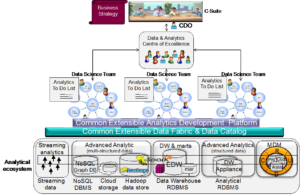
Un fattore chiave è riconoscere che ci vuole molto di più della tecnologia per risolvere questo problema. In effetti, la parte più difficile è organizzare le persone. Qual è l’approccio migliore all’organizzazione per avere successo? In tutta Europa, abbiamo già visto che le organizzazioni IT centralizzate non sono riuscite a tenere il passo con le richieste del business. Allo stesso modo, anche precipitarsi dall’altra parte dello spettro e creare un’organizzazione distribuita di più team indipendenti dipartimentali o di business unit è meno ottimale e causa un eccesso di spesa tecnologica, la re-invenzione e, in una certa misura, il caos dei dati dovuto alla diffusione della preparazione dei dati self-service ovunque. Dopo aver esaminato di recente le installazioni presso uno dei miei clienti, la conclusione è stata che quasi tutti stavano integrando ciecamente i dati senza alcun tentativo di capire quello che stavano creando. In pratica, il selvaggio West di cui sopra. Ma deve esserci una via di mezzo. Se si intende accelerare il processo end-to-end dai dati al valore, credo che ci debba essere una struttura organizzativa federata dall’alto verso il basso guidata da un chief data officer (CDO) che organizza un programma di lavoro per aiutare a raggiungere obiettivi aziendali strategici ad alta priorità.
Customer experience
In un recente sondaggio condotto su 500 imprese, il miglioramento della customer experience è stato indicato come il business driver strategico numero uno per gli investimenti in dati e analisi. Allora, ci si potrebbe pertanto chiedere:
- Quali set di dati dovrebbero essere creati per migliorare la customer experience?
- Quali modelli predittivi devono essere costruiti per migliorare la customer experience?
- Quali modelli prescrittivi devono essere costruiti per formulare automaticamente raccomandazioni che migliorino la customer experience?
- Quali dovrebbero essere eseguiti in tempo reale?
- Quali dovrebbero essere eseguiti in batch?
- Quali dovrebbero funzionare all’edge? O sul cloud? O nel data center?
- Quali report e dashboard di BI devono essere creati per migliorare la customer experience?
Organizzazione e orchestrazione
Come si può vedere, un’intera famiglia di oggetti deve essere costruita per migliorare la customer experience. La domanda successiva è: chi sta costruendo cosa e in quale ordine? E si può fare usando un data fabric dati comune e un catalogo dati usando una piattaforma di sviluppo analitica comune? O almeno, se i componenti vengono creati utilizzando tecnologie diverse, chi gestisce il controllo della versione di tutte queste cose e orchestra tutti questi componenti per testare e distribuire automaticamente e continuamente tutto su base continua per realizzarlo? Sono necessari sia l’organizzazione sia l’orchestrazione per consentire l’approccio DataOps di sviluppo continuo e di implementazione continua (CI/CD). Ciò significa che i software di data fabric (ETL e strumenti di preparazione dei dati self-service compresi), gli strumenti di data science e gli strumenti di BI devono tutti integrarsi con una comune funzionalità di gestione delle versioni come GitHub e con tecnologie DevOps come Jenkins per automatizzare i test e l’implementazione al fine di consentire DataOps. Inoltre, tutti questi componenti devono essere registrati in un catalogo come servizi in modo che possano essere trovati e riutilizzati come e quando necessario. Alcuni vendor lo stanno già facendo. Inoltre, diversi prodotti Data Fabric offrono oggi l’orchestrazione per collegare questi componenti insieme in una pipeline CI/CD di tipo end-to-end, in modo da poter gestire lo sviluppo dei componenti in diversi team e automatizzare i test e l’implementazione, allo scopo di ridurre il time to value.